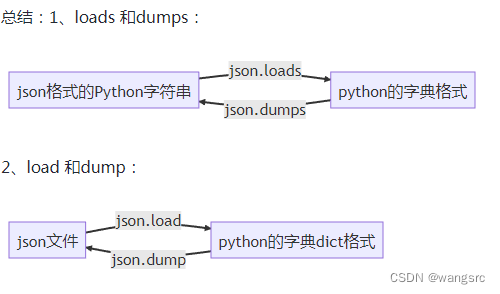
一、引言
随着工业4.0时代的来临,离散制造行业正面临数字化转型的关键节点。离散制造的特点是小批量、多品种、高复杂度,如何实现高效、精准的数据采集与分析,提升生产效率和产品质量,成为行业亟待解决的问题。边缘计算网关作为一种新型的计算模式,能够在数据源头实现数据的实时处理和分析,为离散行业的数据采集提供了有效的解决方案。
二、离散行业数据采集的挑战
离散制造行业具有产品多样、工艺流程复杂、设备种类繁多等特点,数据接口不统一、网络环境复杂,传统的数据采集方式往往存在实时性差、数据不准确、传输效率低等问题。因此,急需一种能够适应离散行业特点的数据采集解决方案。
边缘计算网关解决离散行业数采的方案" height="256" src="https://img-blog.csdnimg.cn/img_convert/1b5b78e275af4b0313552483590fb33f.jpeg" width="400" />
三、边缘计算网关的优势
边缘计算网关作为一种部署在网络边缘的计算设备,具有以下优势:
实时性:在数据源头进行实时处理,减少数据传输延迟,加快决策速度。
灵活性:支持多种通信协议和数据格式,适应离散行业多样化的设备环境。
安全性:通过边缘侧的数据预处理和过滤,降低数据传输过程中的安全风险。
节省带宽:仅传输必要和关键数据,减少数据传输量,降低网络负担。
四、利用边缘计算网关解决离散行业数采的方案
针对离散行业数据采集的挑战,我们提出以下利用边缘计算网关的解决方案:
1. 设备接入与适配层
设备兼容性:确保边缘计算网关能够与离散制造行业中的各种传感器、执行器、PLC等设备进行无缝对接。
协议转换:对于不同设备使用的不同通信协议,边缘计算网关应具备协议转换功能,确保数据能够顺利采集。
动态配置管理:支持远程配置管理,以适应设备变动或新增设备的接入。
2. 数据预处理层
数据清洗:去除异常值、重复值或不符合格式要求的数据,确保数据质量。
数据聚合:将多个数据源的数据进行聚合,形成统一的数据格式和标准。
3. 数据传输与存储层
数据压缩:通过算法压缩数据,减少传输量,提高传输效率。
加密传输:确保数据传输过程中的安全性,防止数据泄露。
边缘存储:支持本地存储,确保在网络不稳定或故障时数据不丢失。
4. 数据分析与应用层
实时监控:提供生产过程的实时监控功能,包括设备状态、生产进度等。
数据分析:对采集的数据上传至云平台进行深入分析,发现生产中的瓶颈和问题,为优化生产提供数据支持。
预测性维护:通过数据分析预测设备可能出现的故障,提前进行维护,减少生产中断。
5. 系统集成与部署
无缝集成:确保边缘计算网关能够与企业现有的IT/OT系统无缝集成。
部署策略:根据企业的实际情况,制定合适的部署策略,如集中部署、分布式部署等。
6. 运维与管理
远程监控:支持远程监控和管理边缘计算网关,确保系统的稳定运行。
故障诊断:通过远程诊断功能,快速定位和解决系统运行中出现的问题。
软件更新与维护:定期发布软件更新,修复已知问题并增加新功能,确保系统的持续进步。
五、实施步骤
1、设备调研与评估:对现有离散制造设备进行调研,评估设备类型、数据接口、通信协议等情况,为后续方案设计和实施提供依据。
2、方案设计与定制:根据调研结果,设计适合离散行业的边缘计算网关解决方案,包括设备接入、数据处理、数据传输等方面的具体实现方式。
3、原型开发与测试:开发原型系统,在模拟环境或试点区域进行测试,验证方案的可行性和稳定性。
4、系统部署与调优:在全面推广前,选取关键区域或生产线进行部署,根据实际应用情况进行调优,确保系统的最佳性能。
5、全面推广与实施:在验证系统稳定性和性能后,逐步在整个离散制造企业中推广实施,实现全面数字化转型。
6、运维与持续优化:建立运维团队,制定运维策略,确保系统的稳定运行;同时,根据实际应用反馈和市场需求,持续优化系统功能和性能。
通过利用边缘计算网关解决离散行业数采的问题,可以显著提高数据采集的效率和质量,推动离散制造企业的数字化转型。未来,随着边缘计算技术的不断发展和完善,相信其在离散制造行业的应用将更加广泛和深入。