基于AI的淡水养殖水质溯源、优化系统方案
- 前言
- 一、关键需求及方案概述
- 二、方案设计
- 预测机制
- LSTM 模型
- 基于intel AI 的时序水质分析模型与分类模型优化
- 三、实战分析
- 1、方案简述
- 2、数据分析
- 预处理
- 特征类型处理
- 特征分布分析
- 3、特征构造
- 4、特征选择
- 过滤法
- 重要性排序
- 5.构建LSTM模型
- 6.模型训练
- 四、Intel Ai Analytics Toolkit 及相关库使用
- Intel ® Modin
- Intel ® Extension for Scikit-learn
- Intel daal4py
- Intel ® XGBoost
- Intel ® Extension for PyTorch
- 功耗更低,速度更快的Tesla T4
- 总结
前言

近年来水产品总产量逐年上升。由于日本排海事件的发酵及不良营销,水产品供需发生变化,淡水水产需求增大,所以加强水产养殖的信息化建设,建立水产养殖监测、预警和管理的综合体系显得十分重要 。水质的安全关乎水产养殖的产量和质量,在养殖过程中,对水质实现动态的监测和预警能提升养殖过程的稳健性。 传统的水质监测系统,存在系统精度低,系统控制延迟高,不能进行预测和提前预警等问题。
本次Intel 黑客松大赛,我基于Intel Ai Analytics Toolkit 及边缘计算设备实现溶氧预测水产养殖监测方案。
一、关键需求及方案概述
传统水产养殖水质监测系统具有不能提前预警、通信延迟高的问题,对于时序数据处理能力较差,核心需解决的是时序数据的分析处理能力。
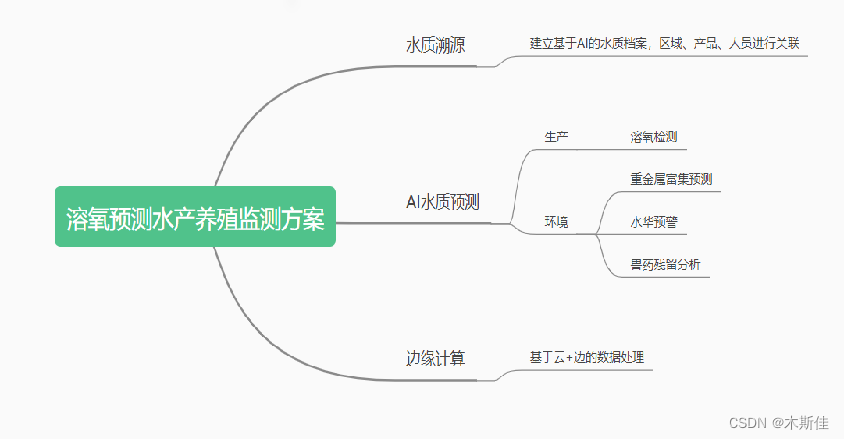
该方案以基于Intel优化的 水质预测算法为核心,针对于不同场景的特征分布进行定向分析,实现水质溯源档案、重金属富集预测、溶氧预测、水华预警预测、兽药残留检测等功能。
其中时序数据,通过物联数据采集模块实现水质数据采集和端处理的功能,采样周期为 1 min。 采集系统电路连接多种传感器获取模拟信号,经过 MCU 识别和计算后将结果值保存到本地寄存器,作为上报的原始数据。
使用Intel Ai Analytics Toolkit 通过对采集数据的处理、分析、训练、预测、实现预测模型。
二、方案设计
预测机制
应用边缘计算的方法,将云服务器的计算和控制任务卸载到上位机,来降低系统控制延迟。 上位机系统实现数据预测的功能,当数据预测或采集数据中出现预警值时,上位机及时向增氧机发出增氧的指令,防范水中出现低氧的情况。 上位机系统配置有预测进程和数据收发进程,两个进程并行计算。同时,上报至云服务的数据会进行二次分析,进行日级别的重金属富集、水华预警预测、兽药残留预测、环境污染检测等模型分析。
下面是溶氧预测的流畅图。

LSTM 模型
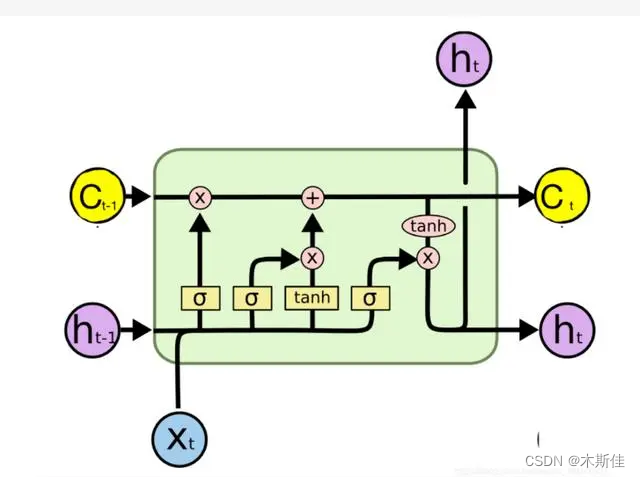
长短时记忆网络( Long short-term memory,LSTM )是一种循环神经网络 (Recurrent neural network, RNN)的特殊变体,具有“门”结构,通过门单元的逻辑控制决定数据是否更新或是选择丢弃,克服了 RNN 权重影响过大、容易产生梯度消失和爆炸的缺点,使网络可以更好、更快地收敛,能够有效提高预测精度。LSTM 拥有三个门, 分别为遗忘门、输入门、输出门,以此决定每一时刻信息记忆与遗忘。输入门决定有多少新的信息加入到细胞当中,遗忘门控制每一时刻信息是否会被遗忘,输出门决定每一时刻是否有信息输出。其基本结构如图所示。
基于intel AI 的时序水质分析模型与分类模型优化
通过针对预测水域质量的数据集,我们从多个角度对其展开分析,包括不限于缺失值分析、异常值分析、不规则分布分析、离散/连续数据分析等。
在分析过程中,我们使用了,
英特尔® Modin 分发版提升pandas处理与探索数据;
英特尔® Extension for Scikit-learn提升基线模型(SVM等)的执行效率;
英特尔® 架构优化的 XGBoost作为我们最终的分类模型进行效果的提升与验证。
三、实战分析
1、方案简述
根据物联设备(本次使用的是开源数据模拟)获取的数据集进行特征构造,用于预测目标水域质量,围绕特征与目标间的关联表现进行特征筛选,利用英特尔® Modin 分发版提升pandas处理特征集的效率,得到了50维相关特征作为最终的入模特证。最后,利用英特尔® 架构优化的XGBoost模型进行二分类。
完成模型后,使用Intel Extension for PyTorch提供的分布式训练功能,利用多台机器和多GPU进行训练。通过使用ipex.distributed.DistributedDataParallel()来包装模型,并在Tesla T4GPU上并行训练数据。
环境配置:

2、数据分析
预处理
首先,获取一份水质监测的离线数据,针对于后续可能实现的污染监测、重金属富集,加入一些随机特征进行模拟。然后将该数据集按照5:2.5:2.5的比例划分为训练集、验证集、测试集。测试集仅在模型推理阶段时使用,可以防止数据穿越等问题的发生,并能够准确对模型关于预测目标的拟合效果进行评估。
特征类型处理
1、划分类别特征, 数值特征
# 划分类别特征, 数值特征
cat_cols, float_cols = [], ['Target']
for col in data.columns:
if data[col].value_counts().count() < 50:
cat_cols.append(col)
else:
float_cols.append(col)
print('离散特征:', cat_cols)
print('连续特征:', float_cols)
离散特征: [‘Color’, ‘Source’, ‘Month’, ‘Day’, ‘Time of Day’, ‘Target’]
连续特征: [‘Target’, ‘pH’, ‘Iron’, ‘Nitrate’, ‘Chloride’, ‘Lead’, ‘Zinc’…]
2、针对离散特征,进行缺失值处理
# 查看缺失值情况
display(data[cat_cols].isna().sum())
missing=data[cat_cols].isna().sum().sum()
print("\nThere are {:,.0f} missing values in the data.".format(missing))
print('-' * 50)
其中像月份属于有序类别特征,如果单纯地映射数字会破坏掉这种有序性,对于这类数据进行单独映射。
......
# 将月份映射至数字1~12
months = ["January", "February", "March", "April", "May",
"June", "July", "August", "September", "October",
"November", "December"]
data['Month'] = data['Month'].replace(dict(zip(months, range(1, len(months) + 1))))
display(data['Month'].value_counts())
......
针对明显无序的类别特征,我们对其进行独特编码处理。对于有序类别特征,我们不对其进行额外处理。
......
# 将无序类别特征进行独特编码
color_ohe = OneHotEncoder()
X_color = color_ohe.fit_transform(data.Color.values.reshape(-1, 1)).toarray()
pickle.dump(color_ohe, open('../feat_data/color_ohe.pkl', 'wb')) # 将编码方式保存在本地
dfOneHot = pandas.DataFrame(X_color, columns=["Color_" + str(int(i)) for i in range(X_color.shape[1])])
data = pandas.concat([data, dfOneHot], axis=1)
......
由于连续变量存在数据缺失的情况,所以我们通过统计每个连续类别对应的中位数对缺失值进行填充。
display(data[float_cols].isna().sum())
missing=data[float_cols].isna().sum().sum()
print("\nThere are {:,.0f} missing values in the data.".format(missing))
# 使用中位数填充连续变量每列缺失值
fill_dict = {}
for column in list(data[float_cols].columns[data[float_cols].isnull().sum() > 0]):
tmp_list = list(data[column].dropna())
# 平均值
mean_val = sum(tmp_list) / len(tmp_list)
# 中位数
tmp_list.sort()
mid_val = tmp_list[len(tmp_list) // 2]
if len(tmp_list) % 2 == 0:
mid_val = (tmp_list[len(tmp_list) // 2 - 1] + tmp_list[len(tmp_list) // 2]) / 2
fill_val = mid_val
# 填充缺失值
data[column] = data[column].fillna(fill_val)
fill_dict[column] = fill_val
特征分布分析
# 针对每个连续变量的频率画直方图
data[float_cols].hist(bins=50,figsize=(16,12))

对于非常不规则的数据进行非线性变换。
# 针对不规则分布的变量进行非线性变换,一般进行log
log_col = ['Iron', 'Zinc', 'Turbidity', 'Copper', 'Manganese']
show_col = []
for col in log_col:
data[col + '_log'] = np.log(data[col])
show_col.append(col + '_log')
# 特殊地,由于Lead变量0值占据了一定比例,此处特殊处理Lead变量
excep_col = ['Lead']
spec_val = {}
# 先将0元素替换为非0最小值,再进行log变换
for col in excep_col:
spec_val[col] = data.loc[(data[col] != 0.0), col].min()
data.loc[(data[col] == 0.0), col] = data.loc[(data[col] != 0.0), col].min()
data[col + '_log'] = np.log(data[col])
show_col.append(col + '_log')
data[show_col].hist(bins=50,figsize=(16,12))
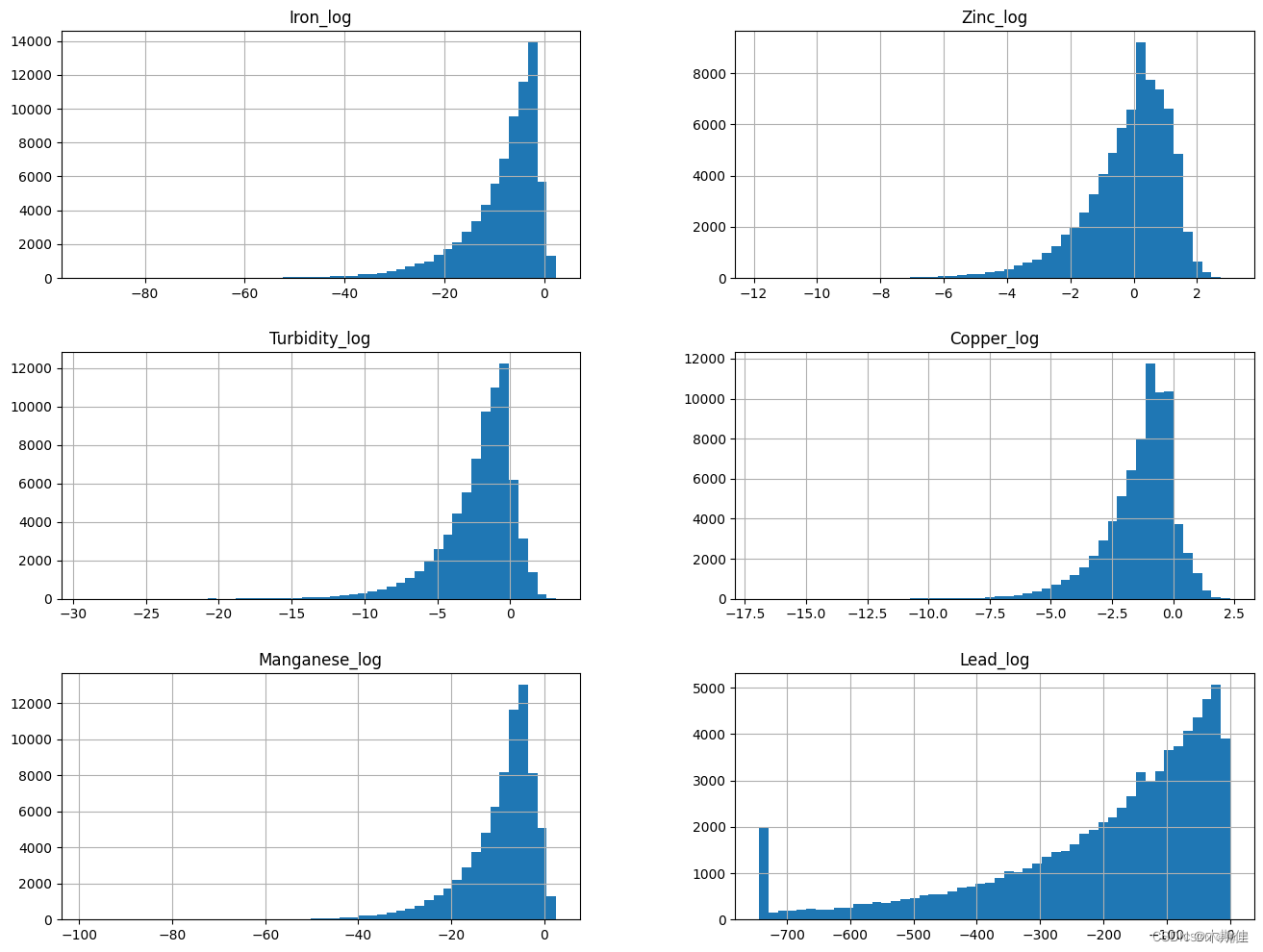
可以发现,上述不规则分布的变量经过log之后已经变成了模型更容易拟合的类正态分布。
3、特征构造
由于特征之间往往隐藏着很多相关的信息等待挖掘,此处进行特征关联,得到新的特征。由于时间关系,此处我们仅以类别特征进行分组,去依次统计其余特征在组内的中位数、均值、方差、最大值、最小值、计数特征,挖掘有效的交互特征。
......
# 特征交互统计
cat_interaction_dict = {}
del_feat_list = []
if 'del_feat_list' in count_fea_dict:
del_feat_list = count_fea_dict['del_feat_list']
add_feat_list = []
for cat_col1 in cat_cols:
if cat_col1 == label_col:
continue
new_col = cat_col1 + '_count'
if new_col not in data.columns and new_col not in del_feat_list:
add_feat_list.append(new_col)
temp = data.groupby(cat_col1).size()
cat_interaction_dict[new_col] = dict(temp)
temp = temp.reset_index().rename(columns={0: new_col})
data = data.merge(temp, 'left', on=cat_col1)
for cat_col2 in cat_cols:
if cat_col2 == label_col:
continue
if cat_col1 == cat_col2:
continue
new_col = cat_col1 + '_' + cat_col2 + '_count'
if new_col not in data.columns and new_col not in del_feat_list:
add_feat_list.append(new_col)
temp = data.groupby(cat_col1)[cat_col2].nunique()
cat_interaction_dict[new_col] = dict(temp)
temp = temp.reset_index().rename(columns={cat_col2: new_col})
data = data.merge(temp, 'left', on=cat_col1)
......
4、特征选择
过滤法
由于本次目标是对淡水质量是否可用进行二分类预测,所以我们针对包含构造特征的所有特征数据,对于离散特征,利用卡方检验判断特征与目标的相关性,对于连续特征,利用方差分析判断特征与目标的相关性,以此做特征集的第一轮筛选。
# 卡方检验对类别特征进行筛选
def calc_chi2(x, y):
import pandas as pd
import numpy as np
from scipy import stats
chi_value, p_value, def_free, exp_freq = -1, -1, -1, []
tab = pd.crosstab(x, y)
if tab.shape == (2, 2):
# Fisher确切概率法, 2✖️2列联表中推荐使用Fisher检验
oddsr, p_value = stats.fisher_exact(tab, alternative='two-sided')
else:
# Pearson卡方检验, 参数correction默认为True
chi_value, p_value, def_free, exp_freq = stats.chi2_contingency(tab, correction=False)
min_exp = exp_freq.min()
if min_exp >= 1 and min_exp < 5:
# Yates校正卡方检验
chi_value, p_value, def_free, exp_freq = stats.chi2_contingency(tab, correction=True)
return chi_value, p_value, def_free, exp_freq
def select_feat_by_chi2(df, cate_cols, target_col, alpha=0.05, cut=99999):
col_chi2_list = []
for col in cate_cols:
chi_value, p_value, def_free, exp_freq = calc_chi2(df[col], df[target_col])
if p_value < alpha:
col_chi2_list.append([col, chi_value])
col_chi2_list = sorted(col_chi2_list, key=lambda x: x[1], reverse=False)
rel_cols = []
for i in range(min(len(col_chi2_list), cut)):
rel_cols.append(col_chi2_list[i][0])
return rel_cols
data = {
'a': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'b': [2000, 2001, 2002, 2001, 2000, 2002],
'Target': [0, 0, 1, 1, 1, 0]
}
df = pd.DataFrame(data)
cols = ['a', 'b']
select_feat_by_chi2(df, cols, 'Target')
# 方差分析法对连续特征进行筛选
def calc_fc(x, y):
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
tab = pd.DataFrame({'group': y, 'feat': x})
tab['group'] = tab['group'].astype('str').map(lambda x: 'g_' + x)
mod = ols('feat ~ group', data=tab).fit()
ano_table = sm.stats.anova_lm(mod, typ=2)
F = ano_table.loc['group', 'F']
p_value = ano_table.loc['group', 'PR(>F)']
return F, p_value
def select_feat_by_fc(df, cate_cols, target_col, alpha=0.05, cut=99999):
from scipy import stats
col_F_list = []
for col in cate_cols:
F, p_value = calc_fc(df[col], df[target_col])
F_test = stats.f.ppf((1-alpha),
df[target_col].nunique(),
len(df[col]) - df[target_col].nunique())
# p值小于显著性水平 or MSa/MSe大于临界值,则拒绝原假设,认为各组样本不完全来自同一总体
if p_value < alpha or F > F_test:
col_F_list.append([col, F])
col_F_list = sorted(col_F_list, key=lambda x: x[1], reverse=False)
rel_cols = []
for i in range(min(len(col_F_list), cut)):
rel_cols.append(col_F_list[i][0])
return rel_cols
data = {
'a': [0.13, 0.09, 0.2, 0.11, 0.13, 0.15],
'b': [2000, 2001, 2002, 2001, 2000, 2002],
'Target': [0, 0, 1, 1, 1, 0]
}
df = pd.DataFrame(data)
cols = ['a', 'b']
select_feat_by_fc(df, cols, 'Target')
重要性排序
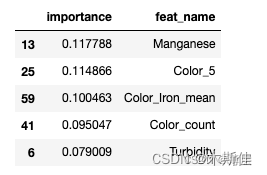
针对第一轮筛选剩余的150维特征,使用模型去进行拟合,并根据最后模型产出的特征重要性从大到小排序,根据重要性以及设定阈值对特征进行第二轮筛选。
# 模型训练函数
def train(data):
## Prepare Train and Test datasets ##
print("Preparing Train and Test datasets")
X_train, X_test, y_train, y_test = prepare_train_test_data(data=data,
target_col='Target',
test_size=.25)
## Initialize XGBoost model ##
ratio = float(np.sum(y_train == 0)) / np.sum(y_train == 1)
parameters = {
'scale_pos_weight': len(raw_data.loc[raw_data['Target'] == 0]) / len(raw_data.loc[raw_data['Target'] == 1]),
'objective': "binary:logistic",
'learning_rate': 0.1,
'n_estimators': 18,
'max_depth': 10,
'min_child_weight': 5,
'alpha': 4,
'seed': 1024,
}
xgb_model = XGBClassifier(**parameters)
xgb_model.fit(X_train, y_train)
print("Done!\nBest hyperparameters:", grid_search.best_params_)
print("Best cross-validation accuracy: {:.2f}%".format(grid_search.best_score_ * 100))
## Convert XGB model to daal4py ##
xgb = grid_search.best_estimator_
daal_model = d4p.get_gbt_model_from_xgboost(xgb.get_booster())
## Calculate predictions ##
daal_prob = d4p.gbt_classification_prediction(nClasses=2,
resultsToEvaluate="computeClassLabels|computeClassProbabilities",
fptype='float').compute(X_test,
daal_model).probabilities # or .predictions
xgb_pred = pd.Series(np.where(daal_prob[:, 1] > .5, 1, 0), name='Target')
xgb_acc = accuracy_score(y_test, xgb_pred)
xgb_auc = roc_auc_score(y_test, daal_prob[:, 1])
xgb_f1 = f1_score(y_test, xgb_pred)
## Plot model results ##
print("\ndaal4py Test ACC: {:.2f}%, F1 Accuracy: {:.2f}%, AUC: {:.5f}".format(xgb_acc * 100, xgb_f1 * 100, xgb_auc))
# plot_model_res(model_name='XGBoost', y_test=y_test, y_prob=daal_prob[:, 1])
importance_df = pd.DataFrame({'importance':xgb.feature_importances_,'feat_name': data.drop('Target', axis=1).columns})
importance_df = importance_df.sort_values(by='importance', ascending=False)
return importance_df
importance_df = train(data)
display(importance_df.head())
针对现有的150维特征对XGB模型进行拟合,并针对输出的特征重要性得分进行排序,将小于阈值的特征进行过滤。
5.构建LSTM模型
LSTM 模型的关键是单元状态,即贯穿图表顶部的水平线。 每个单元就像一个微型状态机,单元三个门的权重在训练过程中学习得到。 遗忘门是
主要由 σ 层组成,σ 层根据 ht-1 和 xt 的输入,通过 sigmoid 激活函数计算信息的丢弃情况,生成一个 0 到 1 之间的结果 ft,0 表示全部丢弃,1 表示
全部保留。 ft 用于与 Ct-1 输入矩阵做点乘运算。 输入门会生成新的信息存储到单元状态中,主要由 σ 层和 tanh 层决定。 通过运算,单元状态从 Ct-1 更新为 Ct。 输出门决定输出的结果,由 σ 层、tanh 层和更新后的单元状态 Ct 共同决定。
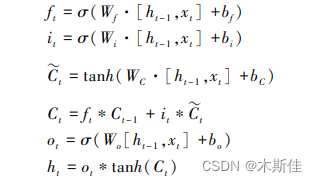
其中: ft、it∗Ct、ht 分别表示 t 时刻单元中遗忘门、输入门、输出门的结果; σ 为 sigmoid 激活函数; W为权重; ht-1 、xt 为 单元输入; bf、bi、bc、bo 均为偏差矩阵;tanh 表示激活函数; Ct-1 为初始单元状态; Ct 为更新后的单元状态; ht 为单元的状态输出;ot 表示输出的信息量
将时间序列转换为监督学习问题
将时间序列形式的数据转换为监督学习集的形式,例如:[[10],[11],[12],[13],[14]]转换为[[0,10],[10,11],[11,12],[12,13],[13,14]],即把前一个数作为输入,后一个数作为对应输出。
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
reframed = series_to_supervised(scaled, 2, 1)
初始化LSTM模型,设置神经元核心的个数,迭代次数,优化器等等
model = Sequential()
model.add(LSTM(27, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dropout(0.5))
model.add(Dense(15,activation='relu'))#激活函数
model.compile(loss='mae', optimizer='adam')
history = model.fit(train_X, train_y, epochs=95, batch_size=2, validation_data=(test_X, test_y), verbose=2,shuffle=False)
6.模型训练
针对经过两轮筛选得到的50维入模特征,使用RandomizedSearchCV对XGBoost的重要参数进行搜索,同时使用StratifiedKFold对模型效果进行交叉验证。
......
import modin.pandas as pd
from modin.config import Engine
Engine.put("dask")
......
from sklearn.preprocessing import OneHotEncoder
from sklearnex import patch_sklearn
patch_sklearn()
......
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import RobustScaler, StandardScaler
from sklearn.metrics import make_scorer, recall_score, precision_score, accuracy_score, roc_auc_score, f1_score
from sklearn.metrics import roc_auc_score, roc_curve, auc, accuracy_score, f1_score
from sklearn.metrics import precision_recall_curve, average_precision_score
from sklearn.svm import SVC
from xgboost import plot_importance
import pickle
......
# 模型训练函数
def train(data):
## Prepare Train and Test datasets ##
print("Preparing Train and Test datasets")
X_train, X_test, y_train, y_test = prepare_train_test_data(data=data,
target_col='Target',
test_size=.25)
## Initialize XGBoost model ##
ratio = float(np.sum(y_train == 0)) / np.sum(y_train == 1)
parameters = {
'scale_pos_weight': len(raw_data.loc[raw_data['Target'] == 0]) / len(raw_data.loc[raw_data['Target'] == 1]),
'objective': "binary:logistic",
'learning_rate': 0.1,
'n_estimators': 18,
'max_depth': 10,
'min_child_weight': 5,
'alpha': 4,
'seed': 1024,
}
xgb_model = XGBClassifier(**parameters)
## Tune hyperparameters ##
strat_kfold = StratifiedKFold(n_splits=3, shuffle=True, random_state=21)
print("\nTuning hyperparameters..")
grid = {'min_child_weight': [1, 5, 10],
'gamma': [0.5, 1, 1.5, 2, 5],
'max_depth': [15, 17, 20],
strat_kfold = StratifiedKFold(n_splits=3, shuffle=True, random_state=1024)
grid_search = RandomizedSearchCV(xgb_model, param_distributions=grid,
cv=strat_kfold, n_iter=10, scoring='accuracy',
verbose=1, n_jobs=-1, random_state=1024)
grid_search.fit(X_train, y_train)
print("Done!\nBest hyperparameters:", grid_search.best_params_)
print("Best cross-validation accuracy: {:.2f}%".format(grid_search.best_score_ * 100))
## Convert XGB model to daal4py ##
xgb = grid_search.best_estimator_
daal_model = d4p.get_gbt_model_from_xgboost(xgb.get_booster())
## Calculate predictions ##
daal_prob = d4p.gbt_classification_prediction(nClasses=2,
resultsToEvaluate="computeClassLabels|computeClassProbabilities",
fptype='float').compute(X_test,
daal_model).probabilities # or .predictions
xgb_pred = pd.Series(np.where(daal_prob[:, 1] > .5, 1, 0), name='Target')
xgb_acc = accuracy_score(y_test, xgb_pred)
xgb_auc = roc_auc_score(y_test, daal_prob[:, 1])
xgb_f1 = f1_score(y_test, xgb_pred)
## Plot model results ##
print("\ndaal4py Test ACC: {:.2f}%, F1 Accuracy: {:.2f}%, AUC: {:.5f}".format(xgb_acc * 100, xgb_f1 * 100, xgb_auc))
# plot_model_res(model_name='XGBoost', y_test=y_test, y_prob=daal_prob[:, 1])
##
importance_df = pd.DataFrame({'importance':xgb.feature_importances_,'feat_name': data.drop('Target', axis=1).columns})
importance_df = importance_df.sort_values(by='importance', ascending=False)
print('model saving...')
pickle.dump(xgb, open("../result/model_best.dat", "wb"))
return importance_df
四、Intel Ai Analytics Toolkit 及相关库使用
Intel ® Modin
本方案使用了Intel ® Modin 分发版提升pandas处理与探索数据;Intel 为Pandas库提供了基于Dask的并行计算功能。通过配置引擎,代码将使用Dask作为默认的并行计算引擎,在使用Pandas或Modin进行数据处理和分析时,将利用Dask的分布式计算能力来加速操作。
Intel ® Extension for Scikit-learn
本方案使用 Intel® Extension for Scikit-learn的目的是提升基线模型(SVM等)的执行效率;
其中,包含使用Intel scikit-learn的StandardScaler进行特征缩放,并使用train_test_split函数进行数据集分割。在完成分割后,函数还将scaler对象保存到文件中,并打印训练集的形状。同时使用了intel优化的NearestNeighbors、RobustScaler等类进行聚类、分类、标准化动作。
Intel daal4py
在oneAPI提供的daal4py模型的加速下,算法的推理速度能得到了更大的提升,同时,在特征选择和模型训练中,当数据集的某些特性不符合特定条件时,需要应用特定的补丁来处理这些特性。PatchingConditionsChain 类提供了一种方便的方式来创建和管理这些补丁条件链。
Intel ® XGBoost
Intel XGBoost的XGBClassifier是一个基分类器,它使用XGBoost算法进行分类任务。该分类器默认使用gbtree作为基分类器,并支持并行计算处理。XGBClassifier和XGBRegressor类提供了nthread参数,用于在训练期间可以使用的线程数。
我们通过调整模型的nthread、n_estimators、learning_rate等参数来优化模型的性能。
Intel ® Extension for PyTorch
首先,使用Intel Scikit-learn库提供的预处理函数来对数据进行归一化,以加速神经网络的训练。可以使用sklearn_ipydnn.Normalize()函数对输入数据进行归一化。
然后,使用Intel Scikit-learn库提供的优化器来替换PyTorch的优化器。例如,sklearn_ipydnn.Adam()函数来替换PyTorch的Adam优化器。这些优化器针对Intel MKL进行了优化,可以加速训练过程。
功耗更低,速度更快的Tesla T4
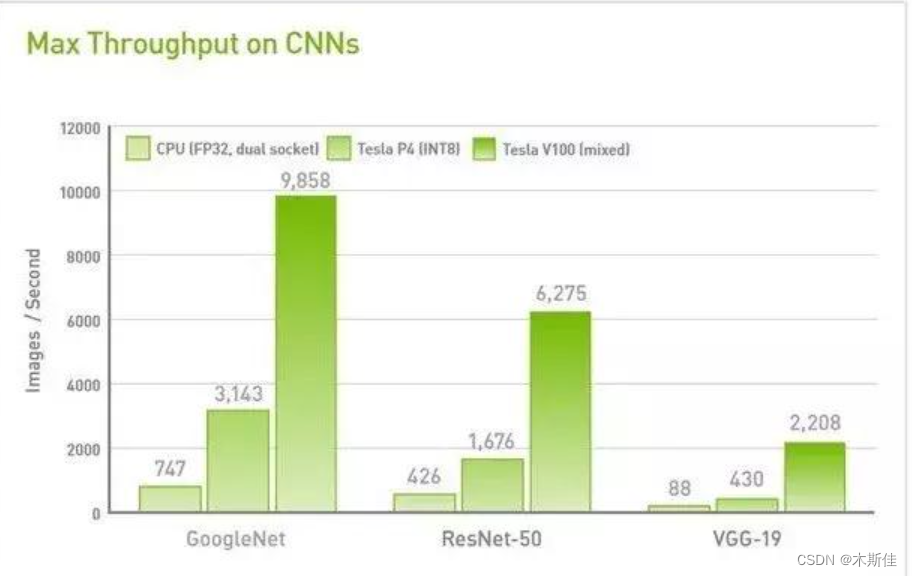
完成模型后,使用Intel Extension for PyTorch提供的分布式训练功能,利用多台机器和多GPU进行训练。通过使用ipex.distributed.DistributedDataParallel()来包装模型,并在Tesla T4 GPU上并行训练数据。
将数据加载到GPU内存中,以加速数据传输和处理。可以使用PyTorch的torch.cuda.is_available()函数检查是否有可用的GPU,然后使用.to(device)方法将数据和模型移动到GPU上。
总结
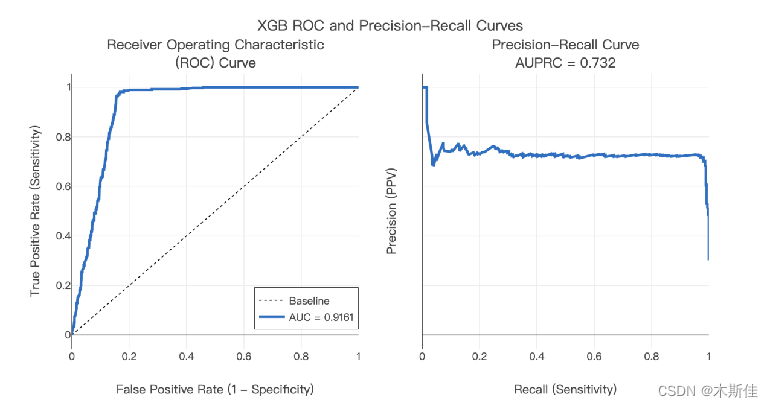
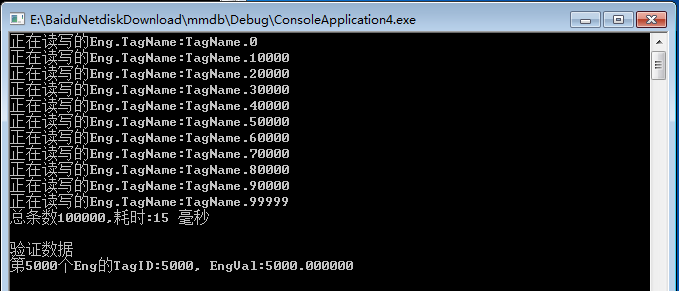
最终,我们经过多次训练,模型在训练集的平均准确率约91.42%,验证集上的准确率达到90.89%,针对单条数据的推理时间为0.03s。针对特殊处理出来的测试集上准确率达到91.21%,最高准确率可达92.99%。上图是其中一次训练结果的展示结果,该结果有力地验证了本模型的有效性。
上述方案我们规划并实现了一个简单的淡水养殖水质溯源系统,同时采用了Intel ® Modin 、Intel ® Extension for Scikit-learn、 Intel daal4py、Intel ® XGBoost、Intel ® Extension for PyTorch、Tesla T4加速等多种手段,大大提高了推理速度和系统鲁棒性,验证了我们提出模型的有效性、高效性、可行性。